- 《精通正则表达式》学习笔记(一) Ch.1 正则表达式入门 Ch.2 入门示例拓展
- 《精通正则表达式》学习笔记(二) Ch.3 正则表达式的特性和流派概览
- 《精通正则表达式》学习笔记(三) Ch.4 表达式的匹配原理
- 《精通正则表达式》学习笔记(四) Ch.5 正则表达式实用技巧
- 《精通正则表达式》学习笔记(五) Ch.6 打造高效正则表达式
- 《精通正则表达式》学习笔记(六) Ch.10 PHP 相关的正则表达式
- 因为 NFA 引擎容许用户进行精确控制,所以我们可以用心打造正则表达式。
- 调校表达式时需要考虑的两个因素是准确性和效率:精确匹配文本而不包含多余的内容,且速度要快。
- 优化表达式的关键在于彻底理解回溯背后的过程,学习些技巧来避免可能的回溯。
- 不同工具可能使用不同的优化措施。如果能够预先判断目标字符串基本无法匹配(例如目标宇符串缺少一个引擎能够预知的,匹配成功必须的字符),足够聪明的实现方式可以完全不应用正则表达式。
- 在分析效率时,不要忘了不同正则引擎的差异。
多选分支的顺序优化
期望:匹配引号字符串(允许转义双引号)
RegEx:"(\\.|[^\\"])*"
- 多选分支的顺序很重要,其会影响回溯的发生与否和发生回溯的先后顺序。
- 调换「
\\.」和「[^\\"]」的顺序,只有在遇到字符串中的转义字符时才会按照多选结构进行回溯,这样增加了第一个多选分支的成功匹配次数,有效减少回溯的次数。 - 为提高效率修改正则表达式时最需要考虑的问题是,改动是否会影响匹配的准确性。在关注效率的时候,万不可忘记准确性。重新安排多选分支的顺序这种操作,只有在排序与匹配成功无关时才不会影响准确性。
- 在任意正则表达式中,星号会对每个普通字符进行迭代(或者说“重复"),重复进入一退出多选结构(和括号)。星号量词作用于括号内的子表达式,每次迭代都需要进入然后再退出括号,因为引擎需要记录括号内的子表达式匹配的文本。为此必须进行处理。
- 优化表达式时,使一次迭代中读入尽可能多的字符,尽量减少发生回溯的次数,把星号迭代的次数减少到最小:

指数级匹配(超线性,super-linear)
- 表达式「
"([^\\"]+|\\.)*"」在 POSIX NFA 中匹配very ...... long时需要超过 3 亿亿亿次回溯。因为正则表达式中某个元素受加号限定的同时,还受括号外的星号限定,无法区分哪个量词控制哪个特殊的字符。 - 对正则表达式「
([^\\"]+)*」来说,加号和星号二者分割(divvy up)字符串的可能性是成指数形式增长的。 - 对不同类型引擎指数级匹配的差异:
- 如果其中的某个表达式,即使不能匹配,也能很快给出结果,那可能就是 DFA。
- 如果只有在能够匹配时才很快出结果,那就是传统型 NFA。
- 如果总是很慢,那就是 POSIX NFA。
回溯实例
匹配成功的回溯
- 从局部来看,回溯就是倒退至未尝试的分支。
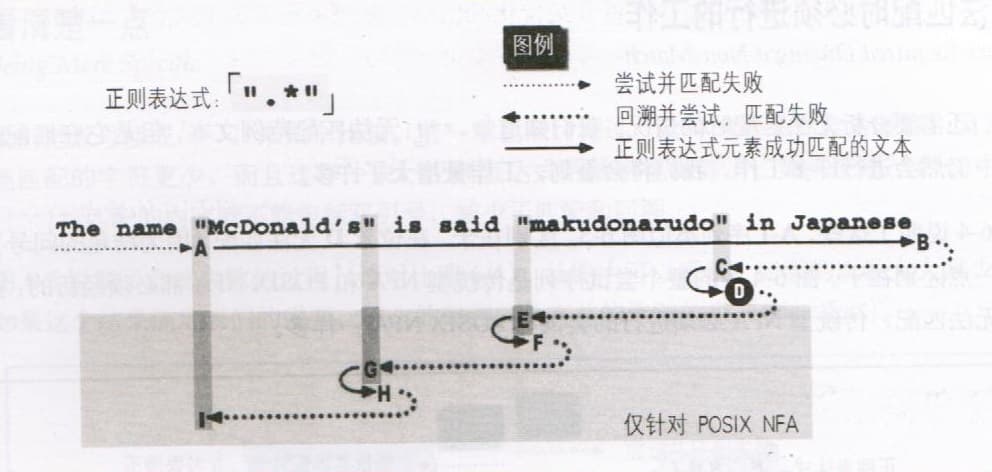
- 表达式「
".*"」在 NFA 引擎中的匹配过程如图所示:- 多次匹配失败直到 A 处
- 从
A-B处均匹配成功,并在每个位置(共计 46 处)撒下面包屑,记录保存状态 - 从
B-C开始逐步回溯,直到C处匹配成功
- 表达式「
".*"」在 POSIX NFA 引擎中的匹配过程与 NFA 类似,但为了确认最长的匹配,还需进行一些确认操作:- 多次匹配失败直到
A处 - 从
A-B处均匹配成功,并在每个位置(共计 46 处)撒下面包屑,记录保存状态 - 从
B-C开始逐步回溯,知道C处匹配成功 - 尝试过程
D-E-F和F-G-H类似B-C-D,只是F和H会被抛弃,因为它们匹配的文本都比D更短 I位置完成当前匹配的所有回溯,重新启动驱动过程,进行下一轮匹配尝试。但由于已经有匹配成功的文本,所以直接返回匹配结果。
- 多次匹配失败直到
无法匹配成功的回溯
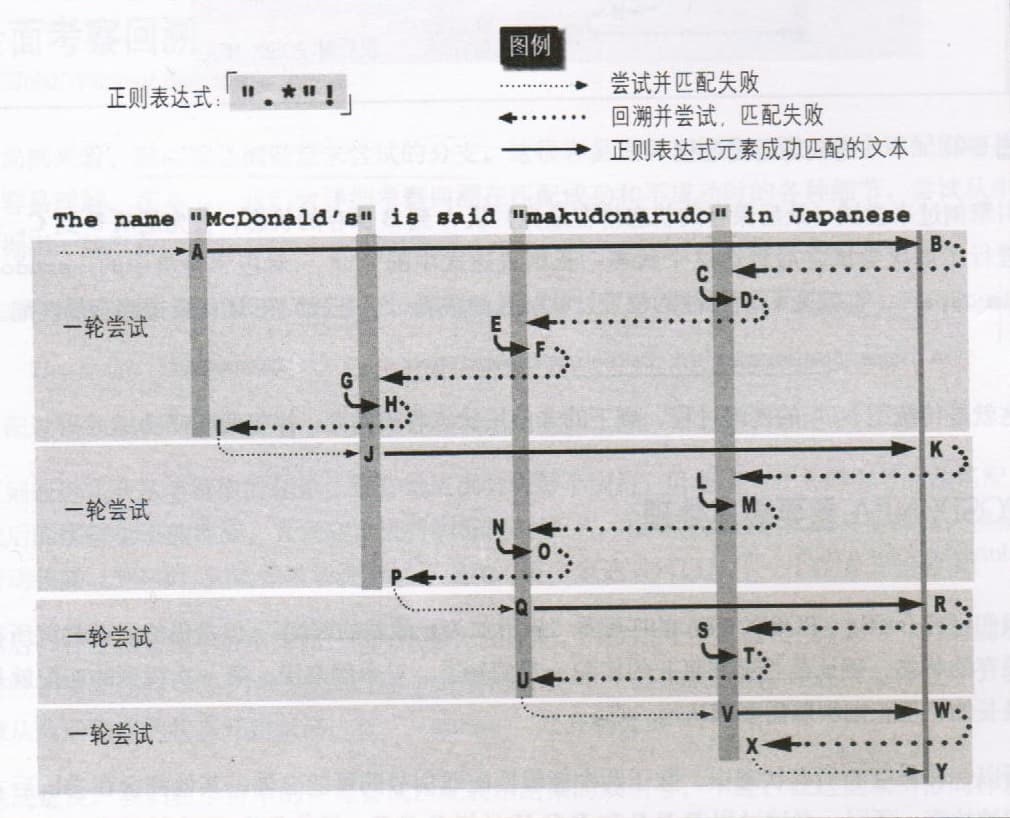
表达式「".*"!」无法匹配范例文本,在匹配过程中进行多轮匹配尝试,每次尝试都有回溯产生,其匹配过程如图所示:
通过优化表达式来减少回溯
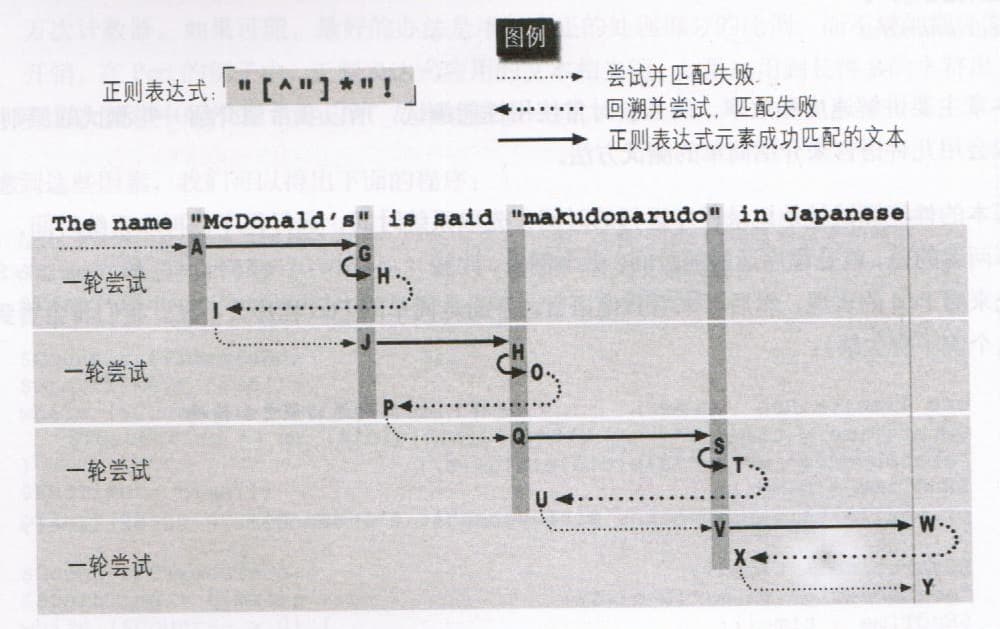
表达式「"[^"]*"!」通过使用「[^"]」来替代「.*」,通过减少可能匹配的字符,从而大大降低了回溯产生的次数。减少的回溯就是有意的伴随效应(side effect)
多选结构的回溯
使用多选结构时,需要注意引起的回溯对性能的影响。
文本:The name "McDonald's" is said "makudonarudo" in Japanese.
期望:makudonarudo
{% raw %}
| RegEx | 回溯次数 |
|---|---|
「[uvwxyz]」 |
34 |
「u|v|w|x|y|z」 |
204 |
常见优化原理
- 提高匹配效率的优化原理主要有:
- 加速某些操作
- 避免冗余操作
- 只有在检测优化措施是否可行所需的时间少于节省下来的匹配时间的情况下,优化才是有益的。
- 优化所需的时间、节省的时间、优化的可能性这三者间存在互相制约的关系。
应用前的优化
- 编译缓存:
- 正则表达式使用之前先进行错误检查,之后编译为内部形式检查字符串。
- 为提高编译效率,首次编译之后的内部形式会被保存或缓存下来,在此后的循坏中复用。
- 集成式处理中的编译缓存:正则表达式可能每次循环都会变化,优化措施是检査插值后的结果(也就是正则表达式的具体值),只有当具体值发生变化时才重新编译。
- 集成式处理中的编译缓存:编译形式与表达式在程序中所处的具体位置相关,正则表达式变化时,先检査插值后的结果(即正则表达式的具体值),当具体值发生变化时才重新编译。
- 程序式处理中的编译缓存:
- 编译形式与表达式在程序中所处的具体位置无关,每次调用函数时,正则表达式必须重新编译。
- 将最近使用的正则表达式模式(regex pattern)缓存后关联到最终的编译形式。
- 调用“应用此表达式”函数之后,作为参数的正则表达式模式会与保存的正则表达式相比较,如果已存在于缓存中,就使用缓存的版本。如果没有,就直接编译这个正则表达式,将其存入缓存。无可用缓存时,丢弃一个最久未使用的编译形式。
- 面向对象式处理中的编译缓存:正则表达式何时编译完全由程序决定。通过构造函数来进行编译。通过对象析构函数抛弃编译好的正则表达式。
- 预查(子)字符串优化:在实际应用正则表达式之前,在目标字符串中快速扫描,检査所需的字符或者字符串一如果不存在,根本就不需要进行任何尝试。
- 长度判断优化:预先判断目标文本的长度是否满足正则表达式要求的最小长度,若不满足,则不进行任何尝试。
传动装置的优化
{% raw %}
| 优化策略 | 释义 | 栗子 |
|---|---|---|
| 字符串起始 / 行锚点 | 任何以「^」开头的正则表达式只能在「^」能够匹配的情况下才可能匹配。 |
「^this|^that」修改为「^(this|that)」或 「^(?:this|that)」 |
| 隐式锚点 | 如果正则表达式以「.*」或「.+」开头,且没有全局性多选结构(global alternation),则可以认为此正则表达式的开头有一个看不见的「^」。则使用上一节的“字符串起始 / 行锚点优化”,节省大量的时间。 |
|
| 字符串结束 / 行锚点 | 遇到末尾为「$」或其他结束锚点的正则表达式时,能够从字符申末尾倒数若干字符的位置开始尝试匹配。 |
「regex(es)?$」从倒数第 8 个字符开始匹配 |
| 开头字符 / 字符组 / 子串识别 | 容许传动装置预先检查字符串中的每个字符,只在可能匹配的位置进行应用,这样能节省大量的时间。避免从错误的位置开始执行匹配尝试。 | 「this|that|other」只能从「[ot]」位置开始匹配 |
| 内嵌文字字符串检查 | 类似初始字符串识别优化,使用高速的 Boyer-Moore 字符串检索算法寻找目标位置。 | |
| 长度识别传动 | 当前位置距离字符申末尾的长度小于成功匹配所需最小长度,传动装置会停止匹配尝试。 |
正则表达式本身的优化
- 文字字符串连接:把多个字符串当作整体而非分离的个体,例如将「
abc」视为整体而非,「a」然后「b」然后「c」。 - 化简量词:约束普通元素的加号、星号之类的量词。避免普通 NFA 引擎的大部分逐步处理开销(step-by-step overhead)。例如「
.*」和「(?:.)*」在逻辑上是相等的,但是在进行此优化的系统中,「.*」实际上更快。 - 消除无必要括号:使用无括号的等价的表达式进行替换。如使用「
.*」替换「(?:.)*」。 - 消除不需要的字符组:将只包含单个字符的字符组在内部进行转换。如「
[.]」转换为「\.」。 - 忽略优先量词之后的字符优化:忽略优先量词通常比匹配优先量词要慢。如果文字字符跟在忽略优先量词之后,只要引擎没有触及那个文字字符,忽略优先量词可以作为普通的匹配优先量词来处理,从而跳过常规的“忽略”状态。
- “过度”回溯检测:限定回溯堆栈的大小,即限定回溯的次数,在“超限”时停止匹配。
- 避免指数级匹配:在匹配尝试进入超线性状态时进行检测,记录每个量词对应的子表达式尝试匹配的位置,绕过重复尝试。
- 使用占有优先量词削减状态:不保留“在此处不进行匹配”的状态,在量词全部尝试完成之后抛弃所有备用状态,每一轮迭代时抛弃上轮的备用状态。否则,如应用「
.*」会在匹配每个字符时创造一个状态,如果字符串很长,会占用大量的内存。 - 量词等价转换:根据不同语言的正则表达式特性,对量词进行替换,如「
\d\d\d\d」替换为「\d{4}」。 - 需求识别:预先取消它认为对匹配结果没有价值的工作。
常见优化方法
{% raw %}
| 优化方法 | 释义 | 栗子 |
|---|---|---|
| 避免重新编译 | 编译和定义正则表达式的次数应该尽可能的少。在循环外创建正则表达式对象,在循环中重复使用。函数式处理要保证循环中使用的正则表达式的数目少于工具所能缓存的上限。集成式处理避免在循环内的正则表达式中使用变量插值。 | |
| 使用非捕获型括号 | 不需要引用的文本,使用非捕获型括号「(?:...)」节省捕获时间,减少回溯使用的状态的数量。 |
|
| 不要滥用括号 | 使用括号会阻止某些优化措施。 | |
| 不要滥用字符组 | 使用元字符来替代单个字符的字符组 | 使用「\.」来替代「[.]」 |
| 使用起始锚点 | 以「.*」开头的正则表达式都应该在最前面添加「^」或者「\A」。配合开头字符 / 字符串 / 字串识别优化,节省不必要的工作。 |
|
| 将文字文本独立出来 | “提取”必要元素:暴露必须的匹配内容。 | 使用「xx*」替代「x+」暴露匹配 x,使用「------{0,2}」替代「-{5,7}」暴露匹配 -。 |
| 将文字文本独立出来 | “提取”多选结构开头的必须元素 | 使用「------{0,2}」替代「-{5,7}」暴露匹配 -。 |
| 将锚点独立出来 | 在表达式前面独立出 ^ 和 \G |
|
| 将锚点独立出来 | 在表达式末尾独立出 $ |
- 如果目标字符串很长:
- 分号接近字符串的开头,使用忽略优先量词。
- 分号接近宇符串末尾的位置,使用匹配优先量词。
- 若是随机数据,又不知道分号接近文首或文尾,则使用匹配优先的量词。
- 如果目标字符串很短,使用何种优先量词无所谓。
- 多个小正则表达式的速度比一个大正则表达式要快得多。
- 在表达式的开头添加合适的环视结构,可以让表达式对文本进行“预査”,选择合适的开始位置。
- 固化分组和占有优先量词能够极大地提高匹配速度,而不会改变匹配结果。
- 主导引擎的匹配
- 将最可能匹配的多选分支放在前头:许多时候多选分支的摆放顺序比优化更重要,但如果顺序与匹配正确无关,就应该把最可能匹配的多选分支放在首位。这一点只对传统型 NFA 引擎且只有存在匹配的时候才适用。对 POSIX NFA 或不存在匹配时,所有的多选分支都必须检测,所以顺序是无关紧要的。
- 将结尾部分分散到多选结构内:把尾部通配表达式加到多选结构之内,匹配时不需要退出多选结构就能发现失败,则匹配失败的更快。
- 各种优化都是平等的,在优化时请务必小心,不要因小失大。