- 《精通正则表达式》学习笔记(一) Ch.1 正则表达式入门 Ch.2 入门示例拓展
- 《精通正则表达式》学习笔记(二) Ch.3 正则表达式的特性和流派概览
- 《精通正则表达式》学习笔记(三) Ch.4 表达式的匹配原理
- 《精通正则表达式》学习笔记(四) Ch.5 正则表达式实用技巧
- 《精通正则表达式》学习笔记(五) Ch.6 打造高效正则表达式
- 《精通正则表达式》学习笔记(六) Ch.10 PHP 相关的正则表达式
正则表达式的发展历程
-
1968 年 Ken Thompson 的文章 Regular Expression Search Algorithm 描述了一种正则表达式编译器,该编译器生成了 IBM7094 的 object 代码。由此也诞生了他的
qed,这种编辑器后来成了 Unix 中ed编辑器的基础。 -
ed有条命令g/Regular Expression/p,读作 Gjobal Regular Expression,Print(应用正则表达式的全局输出)。这个功能最终成为独立的工具grep,之后又产生了egrep(Extended grep)。 -
POSIX(Portable Operating System Interface,可移植操作系统接口)诞生于 1986 年,它是一系列标准,确保操作系统之间的移植性。POSIX 把各种常见的流派分为两大类: Basic Regular Expressions(BREs)和 Extended Regular Expressions(EREs)。POSIX 程序必须支持其中的任意一种。

-
Perl 的特性中值得一提的是,它提供了传统上只有专用工具
sed和awk才提供的正则表达式操作符——这在通用脚本语言中是个首创。正则引擎的代码来自一个早期的项目——Larry 的新闻阅读器rn(其中的正则表达式代码来自 James Gosling 的Emacs。(James Gosling 后来去开发他自己的语言Java,Java 1.4 提供了一个标准的正则表达式包。) -
1997 年 Philip Hazel 开发了
PCRE,这是一套兼容 Perl 正则表达式的库,全面仿制 Perl 的正则表达式的语法和语义。其他的开发人员可以把 PCRE 整合到自己的工具和语言中,许多流行的软件都使用了 PCRE,例如PHP、Apache 2、Exim、Postfix和Nmap。
正则表达式的注意事项和处理方法
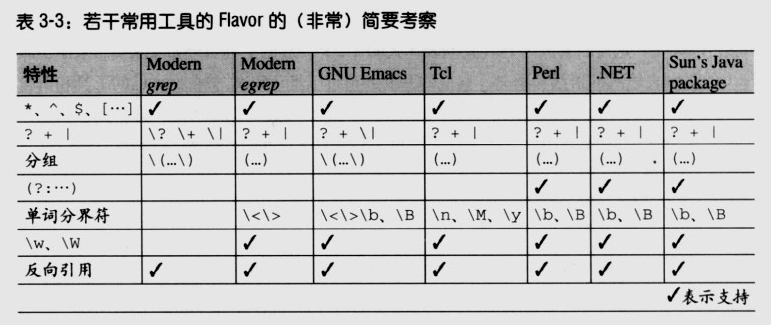
-
一款工具软件能够利用正则表达式实现的功能,通常比它所属的正则流派更重要。
-
程序设计语言有 3 种处理正则表达式的方式:
- 集成式(integrated):直接内建在语言之中,如 Perl。
- 程序式(procedural)
- 面向对象式(object-oriented)
- 程序式和面向对象式,是由普通的函数接收普通的字符串,把它们作为正则表达式进行处理。由不同的函数进行不同的、关系到一个或多个正则表达式的操作。
字符串、字符编码和匹配模式
-
Unicode是一组字符设定,或者是从数字和字符之间的逻辑映射的概念编码。一个 “代码点(code point)”,通常用十六进制来表示,以 “U+” 开头。 -
支持 Unicode 的程序中的正则表达式通常支持
\unum元序列,用来匹配一个具体的 Unicode 字符。 -
Unicode Version 3.1 诞生于 2001 年中期,增加了
u+FFFF之后的代码点。例如,代表音乐谱号C(Clef)的字符对应代码点U+1D121。之前那些仅支持低于U+FPPP字符的程序无法处理这种情况。大多数程序的\unum只能支持最多 4 位十六进制数值。 -
能够处理这类新字符的程序通常提供了
\x{nuwm}序列,num可以为任意多位数字(这是为了增强只支持 4 位数字的\unum表示法)。你可以使用\x{1D121}来匹配这类 “谱号C” 之类的字符。 -
正则模式和匹配模式
- 不区分大小写的匹配模式:在匹配过程中会忽略字母的大小写。
- 宽松排列和注释模式:忽略字符组外部的所有空白字符。字符组内部的空白字符仍然有效,
#符号和换行符之间的内容视为注释。 - 点号通配模式(dot-match-all match mode,也叫 single-line mode “单行模式 "):点号不受限制,可以匹配任何字符,包括换行符。修改了点号处理换行符的方式,从 “需要特殊处理” 变为 “不需要特殊处理”
- 增强的行锚点模式(Enhanced line-anchor match mode,也叫 “多行文本模式 "):「
^」能够匹配字符串中内嵌的文本行的开头位置,「$」能够匹配字符串中内嵌的文本行的换行符。改变了「^」和「$」匹配换行符的方式,从 “不需要特殊处理” 变为 “需要特殊处理”。 - 文字文本模式:几乎不识别任何正则表达式元字符。
常用的元字符和特性
- 字符表示法
- 字符缩略表示法:
\n、\t、\a、\b、\e、\f、\r、\v… - 八进制转义:
\num - 十六进制 /Unicode 转义:
\xnum、\x{num}、\unum、\Unum… - 控制字符:
\cchar
- 字符组及相关结构
- 普通字符组:
[a-z]和[*a-z] - 几乎能匹配任何字符的元字符:点号
- 单个字节:
\C - Unicode 组合字符序列:
\X - 字符组缩略表示法:
\w、\d、\s、\W、\D、\S - Unicode 属性、区块和分类:
\p{Prop}、\P{Prop} - 字符组运算符:
[[a-z]&&[^aeiou]]
-
锚点及其他 “零长度断言”
- 行 / 字符串起点:
^、\A - 行 / 字符串终点:
$、\Z、\z - 本次匹配的开始位置(或者上次匹配的结束位置):
\G - 单词分界符:
\b、\B、\<、\>… - 顺序环视
(?=…)、(?!…); - 逆序环视
(?<=…)、(?<!…)
- 行 / 字符串起点:
-
注释和模式修饰词
- 模式修饰词:
(?modifier),例如(?i)或(?-i) - 模式作用范围:
(?modifier:…),例如(?i:…) - 注释:
(?#…)和#… - 文字文本范围:
\Q…\E
- 模式修饰词:
-
分组,捕获,条件判断和控制:
- 捕获 / 分组括号:
(…)、\1、\2,… - 仅用于分组的括号:
(?:…) - 命名捕获:
(?<Name>…) - 固化分组:
(?>…)永远也不会 “交还” 分组内已经匹配的任何内容。 - 多选结构:
…|…|… - 条件判断:
(?if then|else) - 匹配优先量词:
*、+、?、{num,num}贪心(greedy)模式,默认的量词匹配模式,匹配尽可能多的内容。 - 忽略优先量词:
*?、+?、??、{num,num)?懒惰模式,匹配尽可能少的内容,只需要满足下限,匹配就能成功。 - 占有优先量词:
*+、++、?+、{nuwm,nuwm}+类似固化分组,一旦匹配某些内容,就不会“交还”。
- 捕获 / 分组括号:
-
固化分组就是一个只进不出的栈,被匹配入栈的内容不会交还,这导致若匹配了更多无关内容,将导致匹配失败(因为之前的匹配无法交还),最终的匹配结果将为空。例如:
!.+!可以匹配!Hola!,但!(?>.+)!无法匹配!Hola!。其首先匹配尽可能多的内容Hola!,但是之后的!无法匹配,会强迫.+释放之前匹配的!,但固化分组无法释放,最终导致匹配失败。 -
所有的正则引擎都不会对单词进行语意分析:它们认为 “NE14AD8” 是一个单词,而 “M.I.T.” 不是。