- 《精通正则表达式》学习笔记(一) Ch.1 正则表达式入门 Ch.2 入门示例拓展
- 《精通正则表达式》学习笔记(二) Ch.3 正则表达式的特性和流派概览
- 《精通正则表达式》学习笔记(三) Ch.4 表达式的匹配原理
- 《精通正则表达式》学习笔记(四) Ch.5 正则表达式实用技巧
- 《精通正则表达式》学习笔记(五) Ch.6 打造高效正则表达式
- 《精通正则表达式》学习笔记(六) Ch.10 PHP 相关的正则表达式
Ch.1 正则表达式入门
正则表达式介绍
- 正则表达式(Regular Expression)是经过专门编写的文本字符串,用来匹配字符串(尤其是文件内字符串)集合中符合该模式的所有字符串。RegEx 能够添加、删除、分离、叠加、插入和修整各种类型的文本和数据。
- 完整的正则表达式由两种字符构成:
- 特殊字符(如 *),称为 元字符(metacharacters)
- 其他字符为称为 文字(literal),或是普通文本字符(normal text characters)
- 写正则表达式时,我们需要在对欲检索文本的了解程度与检索精确性之间求得平衡。针对某个检索文本,正则表达式基本不可能匹配不期望的结果,使用它就是合理的。
RegEx 语法基础
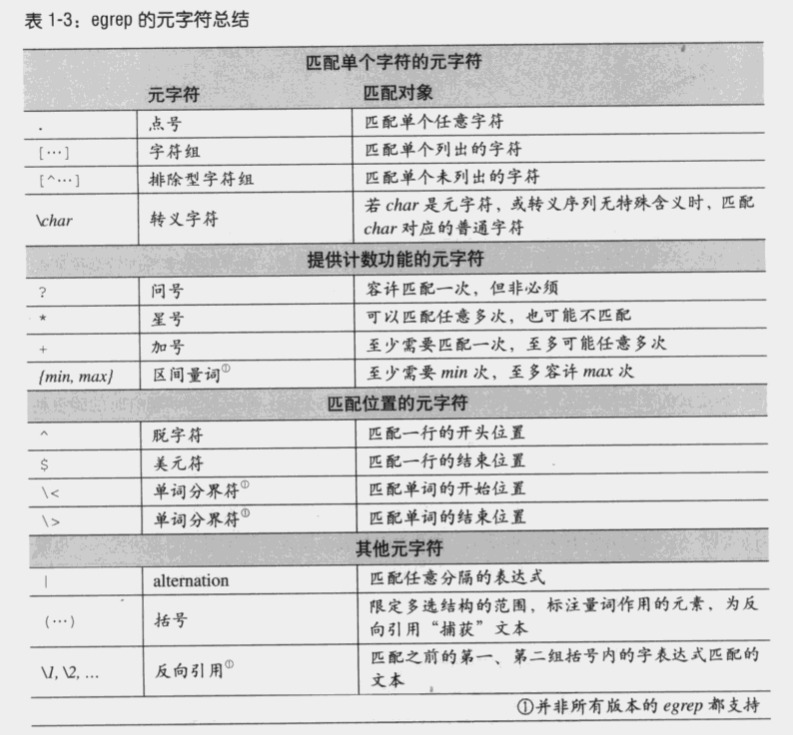
- 只有在字符组内部,连字符
-才用来表示范围。 - 只有在字符组内部(且在字符组首位),脱字符
^才作为一个元字符。 - 只有在在字符组外部,脱字符
^用来表示一个行锚点(line anchor) - 只有在在字符组外部,点号
.才作为一个元字符。 [^x]的含义不是「只有当这个位置不是 x 时才能匹配」,而是「匹配一个不等于 x 的字符」。前者含义可以匹配空行,后者不可。
Ch.2 入门示例拓展
Prel 语法基础
- Perl 表达式及运行参数
| 字符 | 含义 |
|---|---|
=~ |
连接 RegEx 和待搜索的目标字符串 |
= |
运算符,变量赋值 |
== |
运算符,测试两个数值是否相等 |
-p |
表示对目标文件的每一行进行查找和替换 |
-i |
表示整个程序接在命令后面 |
-e |
表示将替换结果写回文件 |
-w |
表示严格检查语法并显示警告 |
举个栗子,下面的 Perl 程序用于将所有 sysread 替换为 read。
```
% perl -p -i -e -w 's/sysread/read/g' file
```
Prel 中 RegEx 的使用
-
Perl 语句说明
$var =~ m/regex/将判断一个正则表达式是否能匹配某个字符串。m表示匹配(match),斜线用来标注正则表达式的边界(其本身不属于正则表达式)。整个测试语句作为一个单元,返回 true 或 false 值。类似的,$var =~ s/regex/replacement/将使用一个正则表达式来匹配并替换某个字符串。s表示替换(substitution,也叫查找和替换(search and replace))。$var =~ qr/regex/将一个正则表达式生成为一个“regex 对象(regex object)”,作为变量保存,供后续使用。
举个栗子:
$reply =~ m/^[0-9]+$/ $reply =~ s/Jeff/Jeffrey/ -
Perl 的模式修饰符 模式修饰符,跟在表示结尾的斜线之后的参数。
| 字符 | 含义 |
|---|---|
/i |
表示此测试不区分大小写(ignore) |
/g |
表示全局匹配(global match/replacement) |
/m |
表示允许使用增强的行锚点(emhanced line anchor),可将 ^ 和 $ 从字符串模式切换到逻辑行模式,即以逻辑换行进行锚位匹配。 |
/x |
表示宽松排列的表达式(free-form expressions),可用于多行正则表达式增强可读性 |
举个栗子:
$reply =~ m/^[0-9]+$/i
$reply =~ m/^[0-9]+$/g
$reply =~ m/^[0-9]+$/x
RegEx 语法基础
正则匹配符
| 字符 | 含义 |
|---|---|
\t |
制表符 |
\n |
换行符 |
\r |
回车符 |
\s |
任何 空白 字符(如空格符、制表符、进纸符等) |
\S |
除 \s 之外的任何字符 |
\w |
[a-zA-Z0-9](在 \w+ 中很有用,可以用来匹配一个单词) |
\W |
除 \w 之外的任何字符 |
\d |
[0-9],即数字 |
\D |
除 \d 之外的任何字符 |
^ |
行起始锚位符 |
$ |
行结束锚位符 |
ps.^$ 可用来匹配空行,因为空行的行起始和行结束是相连的。
分组
使用 (…) 用来分组并捕获,使用 (?:…) 来分组但不捕获。
捕获顺序按照括号出现的先后顺序依次进行,而非内外顺序。
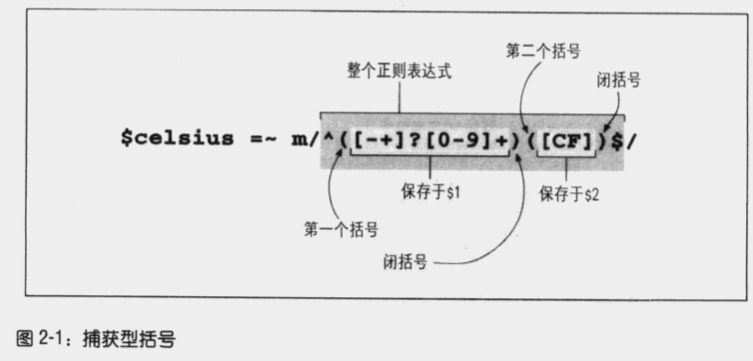
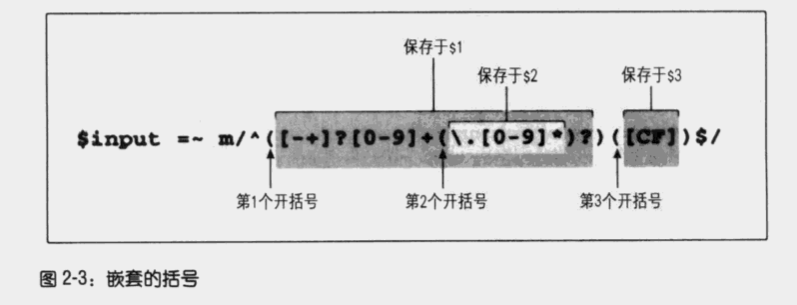
- 思考
$var =~ s/\bJeff\b/Jeff/i上述 Perl 表达式中i仅对所有匹配的字符串生效,对 replacement 的文本没有影响。即匹配所有 jeff、Jeff、jEFF……替换为 Jeff。$price =~ s/(\.\d\d[1-9]?)\d*/$1/上述 Perl 表达式将数字文本格式化为保留两位小数,且如果第三位非零则保留第三位。即 12.375000000564 => 12.375,12.375 => 12.375,37.5000 => 37.50。
环视
环视结构不匹配任何字符,只匹配文本中的特定位置,类似单词分界符 \b,锚点 ^ 和 $。
环视结构的主体为要求的文本,而非匹配的文本,即使用环视时,环视结构内的文本将不会被匹配,而是作为标记文本位置的特殊语法进行使用。
| 字符 | 名称 | 别名 | 作用 | 条件 |
|---|---|---|---|---|
(?:…) |
非捕获型分组 | 分组但不捕获 | ||
(?=…) |
肯定顺序环视 | 正前瞻 | 环视文本后的文本是否为要求文本 | 子表达式能够匹配右侧文本 |
(?!…) |
否定顺序环视 | 反前瞻 | 环视文本后的文本是否非要求文本 | 子表达式不能匹配右侧文本 |
(?<=…) |
肯定逆序环视 | 正后顾 | 环视文本前的文本是否为要求文本 | 子表达式能够匹配左侧文本 |
(?<!…) |
否定逆序环视 | 反后顾 | 环视文本前的文本是否非要求文本 | 子表达式不能匹配左侧文本 |
环视在检查子表达式能否匹配的过程中,其本身不会 占用 任何文本。
e.g.匹配文本为 Jeffrey,使用如下 RegEx 时匹配结果不同:
Jeffrey #匹配 Jeffrey
(?=Jeffrey)Jeff #定位 Jeffrey 中 Jeff 和 rey 的中间位置,匹配 Jeffrey 中的 Jeff
Jeff(?=rey) #与上式等价
\bJeff(?=s\b) #定位 Jeffs 中 Jeff 和 s 的中间位置,匹配 Jeffs 中的 Jeff
(?<=\bJeff)(?=s\b) #定位 Jeffs 中 Jeff 和 s 的中间位置,且并未匹配任何内容
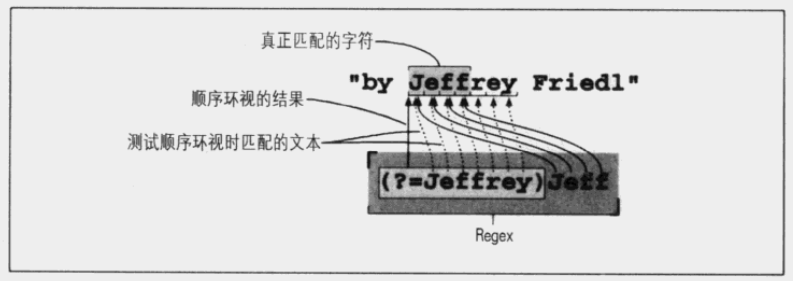
(?=Jeffrey)Jeff 的匹配
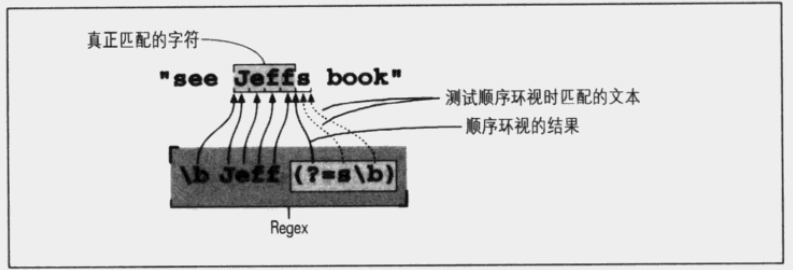
\bJeff(?=s\b) 的匹配
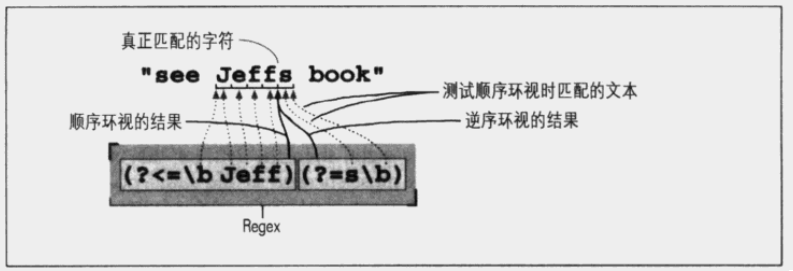
(?<=\bJeff)(?=s\b) 的匹配
- 思考 如何使用 Perl 表达式将数字文本格式化为右起三位数逗号分隔的数字。即 375000000564 => 375,000,000,564?
-
$var =~ s/(?<=\d)(?=(\d\d\d)+$)/,/g;(?<=\d)表示左侧必须有数字,方式出现 ,375,000,000,564(?=(\d\d\d)+$)表示从最右方进行肯定逆序环视(正后顾),每看到三个数字进行一次环视标记。 -
$var =~ s/(\d)(?=(\d\d\d)+$)/$1,/g;(\d)使用捕获型括号实现逗号前的内容分组,然后保持 $1 内容不变,在其后添加逗号 -
$var =~ s/(\d)((\d\d\d)+\b)/$1,$2/g;上式不使用环视,但无法实现期望。最终得到类似 375000000564 => 375,000000564。((\d\d\d)+\b)匹配的数字属于最终匹配文本,不能作为“未匹配的部分”,供/g的下一次匹配迭代使用。 如欲使用该式进行实现,可配合循环结构:
while ($var =~ s/(\d)((\d\d\d)+\b)/$1,$2/g) {
#空结构体,使用条件操作
}
\b([a-z]+)((?:\s|<[^>]+>)+)(\1\b)上适用于匹配一段文本中连续出现的重复单词,具体示意如下图: