Scan 命令
- 使用
keys命令来查找特定前缀的 key 列表有两个缺点:- 没有
offset、limit参数,该命令会一次性输出所有满足条件的结果。 keys命令的时间复杂度为O(n),大键查询会阻塞进程,造成卡顿。
- 没有
- 通常使用
scan命令来进行大键查询:scan命令的时间复杂度为O(n),但通过游标分步进行,不阻塞进程,游标的唯一状态为返回的游标整数。- 提供
limit参数,实际数量返回可多可少。 - 返回结果可能有重复,需要自行去重。
- 遍历查询时若有数据变动,是否会返回符合条件的数据一切随缘。
- 返回为空不一定表示无结果,要看游标是否为零。
- Scan 命令可以用于各种类型数据的操作,如
zscan用于 zset 集合、hscan用于 hash 字典、sscan用于 set 集合。 - 在集群环境下,如果某个 key 太大,会数据导致迁移卡顿。
- 在内存分配上,如果一个 key 太大,它扩容时会申请更大内存,导致卡顿。
- 开发中,要尽量避免大 key 的产生。
- 假设 redis 中已经存在 10000 条名为 key%d 的数据,下面是一个 scan 的例子:
127.0.0.1:6379> scan 0 match key99* count 1000
1) "13976"
2) 1) "key9911"
2) "key9974"
......
12) "key9905" // 扫描了 1000 个槽位,返回 12 条数据,还有库存
127.0.0.1:6379> scan 13976 match key99* count 1000
1) "1996"
2) (empty list or set) // 扫描了 1000 个槽位,返回为空,还有库存
127.0.0.1:6379> scan 1996 match key99* count 1000
1) "12594"
2) 1) "key9939"
2) "key9941"
...... // 扫描了 1000 个槽位,返回 N+ 条数据,还有库存
127.0.0.1:6379> scan 11687 match key99* count 1000
1) "0"
2) 1) "key9969"
2) "key998"
......
11) "key9944" // 扫描了 1000 个槽位,返回 11 条数据,游标为 0,没有库存啦
- 可以使用
--bigkeys参数定位大键:
|
|
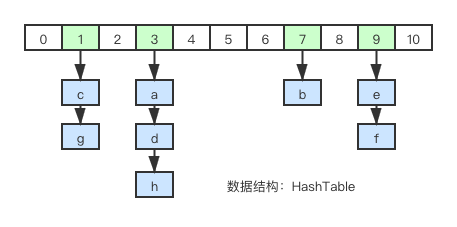
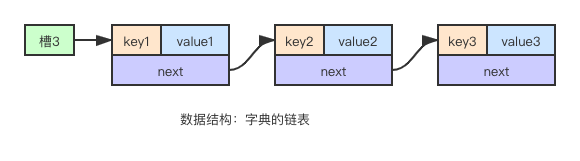
字典结构
-
字典结构的特殊性决定了 Scan 的高效,游标返回的是槽位号码,每个槽位(slot)挂载的元素可多可少,所以有可能出现返回结果为空的情况:
-
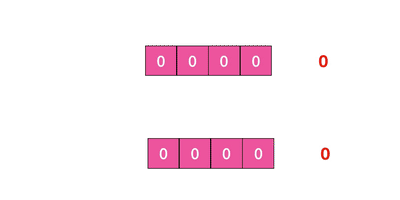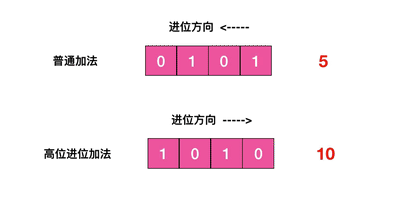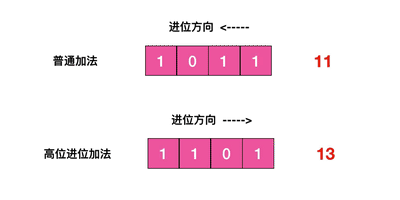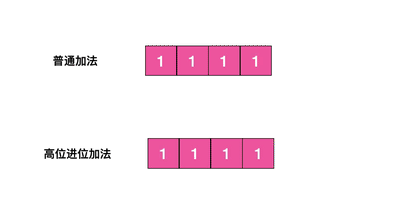
scan 命令以高位进位加法进行检索,与普通加法相反,但也可以遍历所有结果:
字典扩容
-
数组长度为
2^n次方,所以取模运算等价于位与操作,a mod 8 = a & (8-1) = a & 7,7 称为字典的mask值。扩容操作使得原槽位xxx中的一半数据不变还是0xxx,另一半放到了1xxx(xxx+mask)中: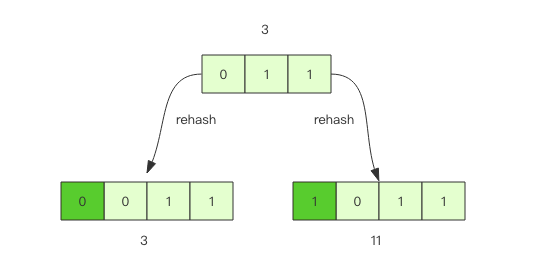
-
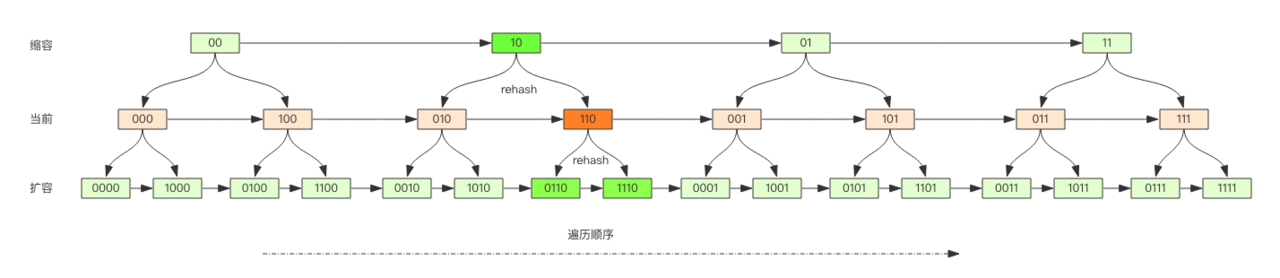
这样的字典伸缩方式使得 scan 按高位加法遍历数组变得无比高效,因为伸缩操作此时对 scan 的遍历方法毫无影响!rehash 后的槽位在遍历时的顺序依然是相邻的!!
-
渐进式 rehash 会同时保留旧数组和新数组,在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上,避免大键伸缩造成卡顿
-
scan 处于 rehash 中的字典,需要同时扫描新旧槽位,然后将结果融合后返回给客户端