关于 RegEx,一直记得一句话:
好的 RegEx 是短而精的。
近来在研究 RegEx 的折腾之路上走来走去。决定把自己所遇到的一些小例子记下来。 一方面方便自己回顾、反思,另一方面给大家参考、指正。 想起前段时间工作上遇到的一个 situation。
源文本如下:
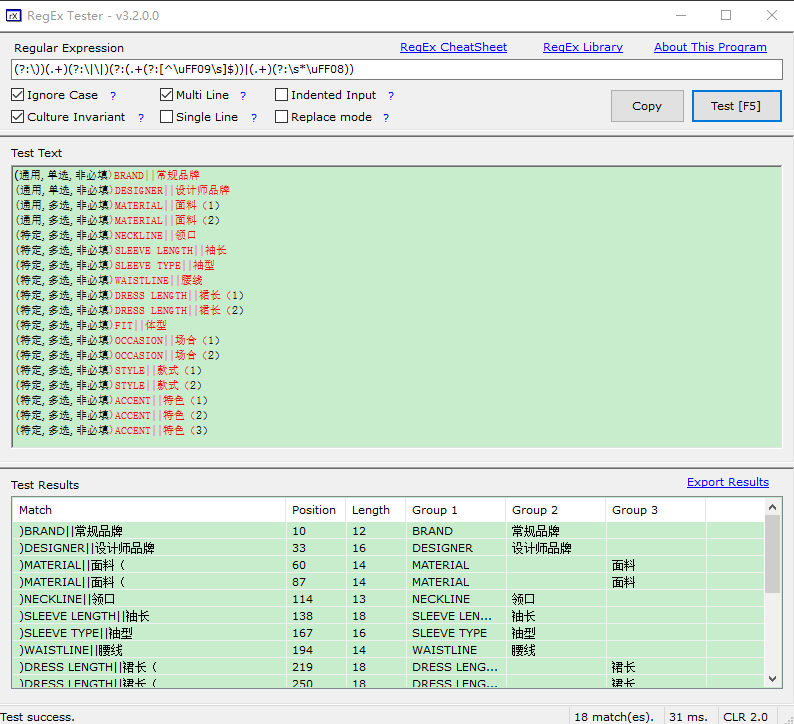
(通用,单选,非必填)BRAND||常规品牌
(通用,单选,非必填)DESIGNER||设计师品牌
(通用,多选,非必填)MATERIAL||面料(1)
(通用,多选,非必填)MATERIAL||面料(2)
(特定,多选,非必填)NECKLINE||领口
(特定,多选,非必填)SLEEVE LENGTH||袖长
(特定,多选,非必填)SLEEVE TYPE||袖型
(特定,多选,非必填)WAISTLINE||腰线
(特定,多选,非必填)DRESS LENGTH||裙长(1)
(特定,多选,非必填)DRESS LENGTH||裙长(2)
(特定,多选,非必填)FIT||体型
(特定,多选,非必填)OCCASION||场合(1)
(特定,多选,非必填)OCCASION||场合(2)
(特定,多选,非必填)STYLE||款式(1)
(特定,多选,非必填)STYLE||款式(2)
(特定,多选,非必填)ACCENT||特色(1)
(特定,多选,非必填)ACCENT||特色(2)
(特定,多选,非必填)ACCENT||特色(3)
需要匹配出每一行中对应的中、英文标题: 如英文标题「SLEEVE LENGTH」,及对应的中文标题「袖长」 如英文标题「DRESS LENGTH」,及对应的中文标题「裙长」
乍一看很简单,但是实际做起来却没有那么容易。写出的 RegEx 总会受到行末的序号所影响。最后使用两个 RegEx 分情况进行匹配:
- 使用下式匹配无序号的情况:
(?:\))(.+)(?:\|\|)(.+(?:[^\uFF09\s]$))
例如能够匹配出 DESIGNER 设计师品牌, FIT 体型
- 使用下式匹配有序号的情况:
(?:\))(.+)(?:\|\|)(.+)(?:\s*\uFF08)
例如能够匹配出 MATERIAL 面料, STYLE 款式
然后使用或关系进行合并:
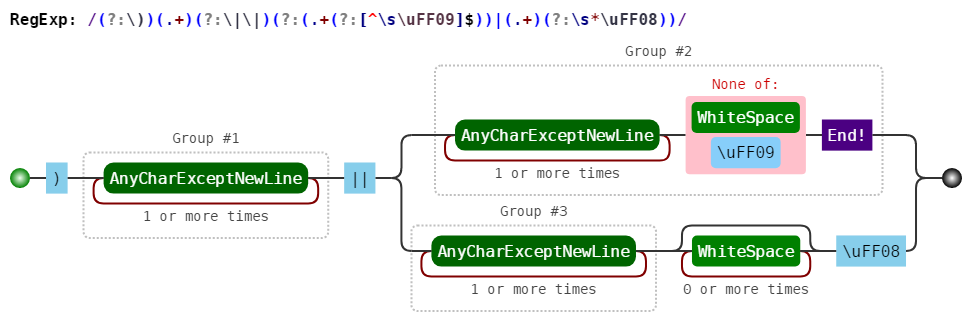
(?:\))(.+)(?:\|\|)(?:(.+(?:[^\uFF09\s]$))|(.+)(?:\s*\uFF08))
匹配结果如下图:
这段正则的释意如下:
(?:\)) #分组但不捕获「非必填」后面的右括号
(.+) #分组1匹配任意内容(即英文)
(?:\|\|) #分组但不捕获双竖线
(?: #分组但不捕获
(.+ #分组2匹配任意内容(即无序号中文)
(?:[^\uFF09\s]$) #分组但不捕获空白符和右括号外的字符
) #分组2结束
| #分组或关系
(.+) #分组3匹配任意内容(即有序号中文)
(?:\s*\uFF08) #分组但不捕获空白符和左括号
) #分组结束
一直没有想到什么好的解决办法能够在一个简短的正则表达式中完美实现这一个需求。如果读者有什么好想法(好吧其实并没什么读者)请评论分享你的 idea。
2017.6.22 更新
感谢 Inoreader 读者 Andy 的评论和建议,其提供的 RegEx 如下:
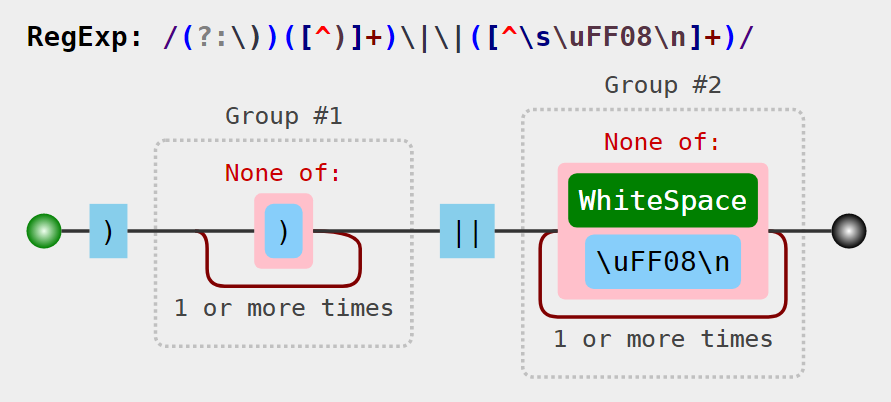
(?:\))([^\)]+)\|\|([^\s\uFF09\n]+)
释意如下:
(?:\)) #分组但不捕获「非必填」后面的右括号
([^\)]+) #分组捕获除右括号之外的内容
\|\| #双竖线
([^\s\uFF09\n]+) #分组捕获除空白符、右括号和换行符外的字符
更近一步精简的版本如下:
([^\)]+)\|\|([^\s\uFF09\n]+)
释意如下:
([^\)]+) #分组捕获除右括号之外的内容
\|\| #双竖线
([^\s\uFF09\n]+) #分组捕获除空白符、右括号和换行符外的字符

总结
(?:\))(.+)(?:\|\|)(?:(.+(?:[^\uFF09\s]$))|(.+)(?:\s*\uFF08))
(?:\))([^\)]+)\|\|([^\s\uFF09\n]+)
([^\)]+)\|\|([^\s\uFF09\n]+)
对比上文的三个 RegEx,可以总结出编写 RegEx 的些许技巧:
- 匹配时有正向和反向两种思路,不一定要写出完整匹配目标文本的特定 RegEx,而可以选择使用排除法进行优化。(如「[1-8]」匹配数字 1-8,,亦可写为「[^90]」匹配除 9 和 0 外的字符)
- 「分组不捕获」无需滥用,如果只提取分组内的内容,则无关未分组内容也无需使用「分组不捕获」,以精简 RegEx。(如本文中的双竖线其实是无需使用分组不捕获的)
- 好的 RegEx 是短而精的。