《Redis深度历险》学习笔记:介绍&基础数据结构
- Redis(Remote Dictionary Service),由意大利人 Salvatore Sanfilippo(网名Antirez)开发。
- Redis 默认端口
6379 是「MERZ」一词在手机九宫格键盘上对应的数字位置。「MERZ」在 Antirez 的朋友圈语言中是「愚蠢」的代名词,它源于意大利广告女郎「Alessia Merz」在电视节目上说了一堆愚蠢的话。
- 字符数组
key <-> value。
- 通常将用户信息结构体使用 JSON 序列化成字符串存入 Redis,取用数据时反序列化。
- string 型是动态字符串,可修改,最大长度为 512M。
- 通常采用加倍扩容预分配原则,减少内存的频繁分配:
<1MB 时翻倍扩容,>1MB 时每次扩容 1MB。
- 如果 string 已经设置了过期时间,但调用 set 方法修改后,过期时间会失效。
- 列表是链表而不是数组,增删速度很快(
O(1)),但索引定位很慢(O(n))。
- 列表的底层结构为**
连续内存存储(ziplist) + 链表(linkedlist)** 的混合结构 quicklist,既满足快速增删,又减少空间冗余。

- hash 是无序字典,底层结构为
数组 + 链表。
- hash 字典的值只能是字符串。
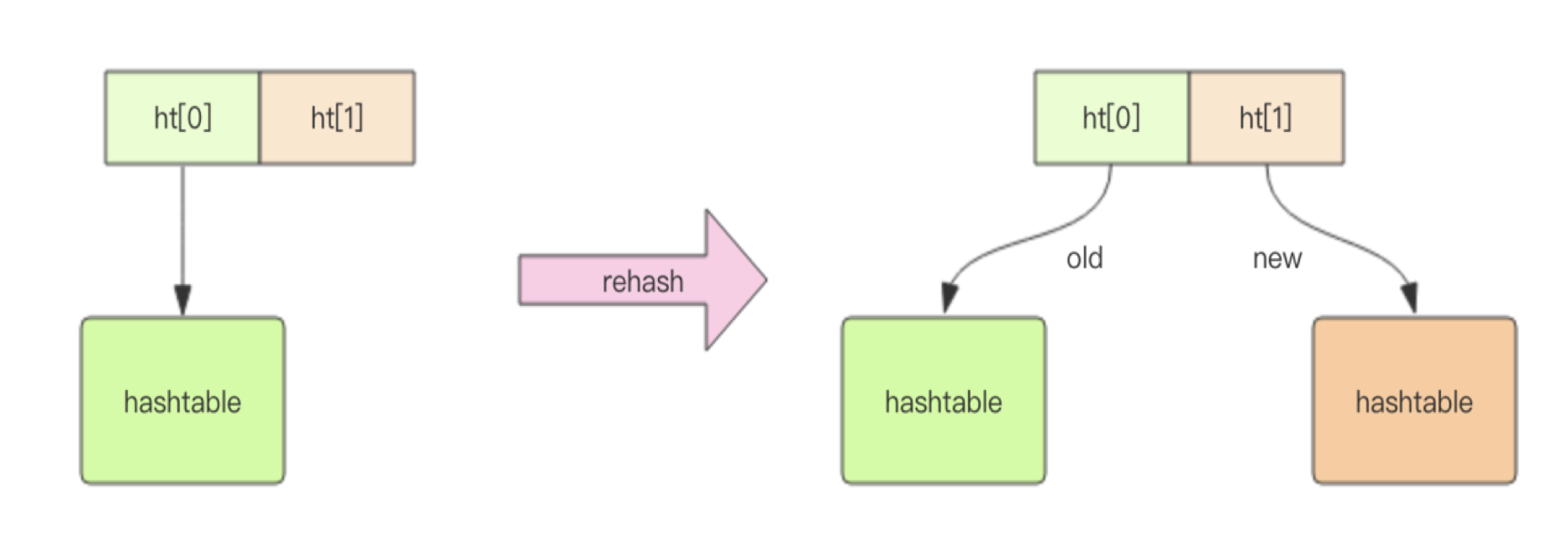
- hash 字典采用渐进式 rehash 策略来保证高性能,避免堵塞。创建新表进行 rehash,旧表持续可读,rehash 完成后删除旧表。
- hash 字典可以对用户结构中的每个字段单独存储,方便部分获取,避免全量获取导致的资源浪费。
- hash 结构的存储消耗高于单个字符串,使用时需考虑成本。
- set 内部的键值对是无序的唯一的,相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
- 移除最后一个元素后,set 自动被删除,内存被回收。
- 由于 set 键值具有唯一性,所以有去重功能。
- zset 为有序列表,可对 value 指定权重值 score 后进行排序。
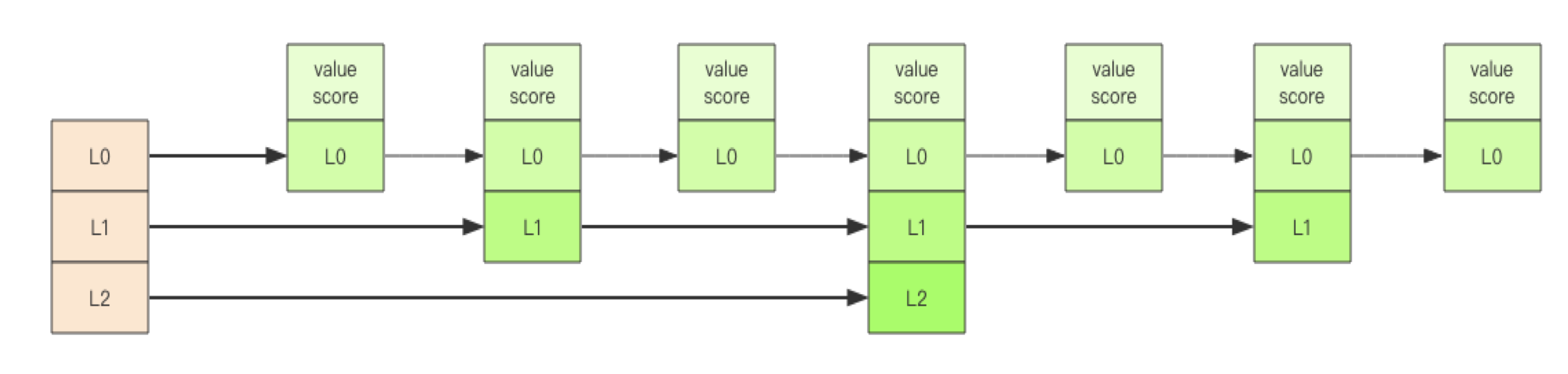
- zset 内部数据结构是「跳跃列表」,为支持随机的增删,使用了类似金字塔结构:底层元素串连,抽取代表值使用一级指针串连,抽取代表值使用二级指针串连……以此类推,最多 32 层。单个节点可能身兼多级职能。
- 跳跃列表采取随机策略来决定新元素的层级位置,层级概率逐级减半:L0 层概率 100%,L1 层 50%,L2 层 25%……
list/set/hash/zset 是容器型数据结构。- 规则一:
create if not exists——如果容器不存在,则先创建新容器再进行操作。
Redis 就会自动创建一个,然后再 rpush 进去新元素。
- 规则二:
drop if no elements——如果容器内无元素,则立即删除容器,释放内存。
- Redis 设置的
过期时间是以对象为单位,而非元素/属性。即 hash 结构过期是整个 hash 对象的过期,并非子 key 过期。